Cloud Native Formats 101
D.03.10 HANDS-ON TRAINING - EarthCODE 101 Hands-On Workshop - Example showing how to access data on the EarthCODE Open Science Catalog and working with the Pangeo ecosystem on EDC
Import Packages¶
from pystac.extensions.storage import StorageExtension
from datetime import datetime
from pystac_client import Client as pystac_client
from odc.stac import configure_rio, stac_load
import xarrayContext¶
When dealing with large data files or collections, it’s often impossible to load all the data you want to analyze into a single computer’s RAM at once. This is a situation where the Pangeo ecosystem can help you a lot. Xarray offers the possibility to work lazily on data chunks, which means pieces of an entire dataset. By reading a dataset in chunks we can process our data piece by piece on a single computer and even on a distributed computing cluster using Dask (Cloud or HPC for instance).
How we will process these ‘chunks’ in a parallel environment will be discussed in dask_introduction. The concept of chunk will be explained here.
When we process our data piece by piece, it’s easier to have our input or ouput data also saved in chunks. Zarr is the reference library in the Pangeo ecosystem to save our Xarray multidimentional datasets in chunks.
Zarr is not the only file format which uses chunk. kerchunk library for example builds a virtual chunked dataset based on NetCDF files, and optimizes the access and analysis of large datasets.
Data¶
In this workshop, we will be using the SeasFire Data Cube published to the EarthCODE Open Science Catalog
Related publications¶
- Alonso, Lazaro, Gans, Fabian, Karasante, Ilektra, Ahuja, Akanksha, Prapas, Ioannis, Kondylatos, Spyros, Papoutsis, Ioannis, Panagiotou, Eleannna, Michail, Dimitrios, Cremer, Felix, Weber, Ulrich, & Carvalhais, Nuno. (2022). SeasFire Cube: A Global Dataset for Seasonal Fire Modeling in the Earth System (0.4) [Data set]. Zenodo. Alonso et al. (2024). The same dataset can also be downloaded from Zenodo: https://
zenodo .org /records /13834057
http_url = "https://s3.waw4-1.cloudferro.com/EarthCODE/OSCAssets/seasfire/seasfire_v0.4.zarr/"
ds = xarray.open_dataset(
http_url,
engine='zarr',
chunks={},
consolidated=True
# storage_options = {'token': 'anon'}
)
dstotal_size_GB = sum(var.nbytes for var in ds.data_vars.values()) / 1e9 # B to GB
print(f"Total size: {total_size_GB:.2f} GB")What is a chunk¶
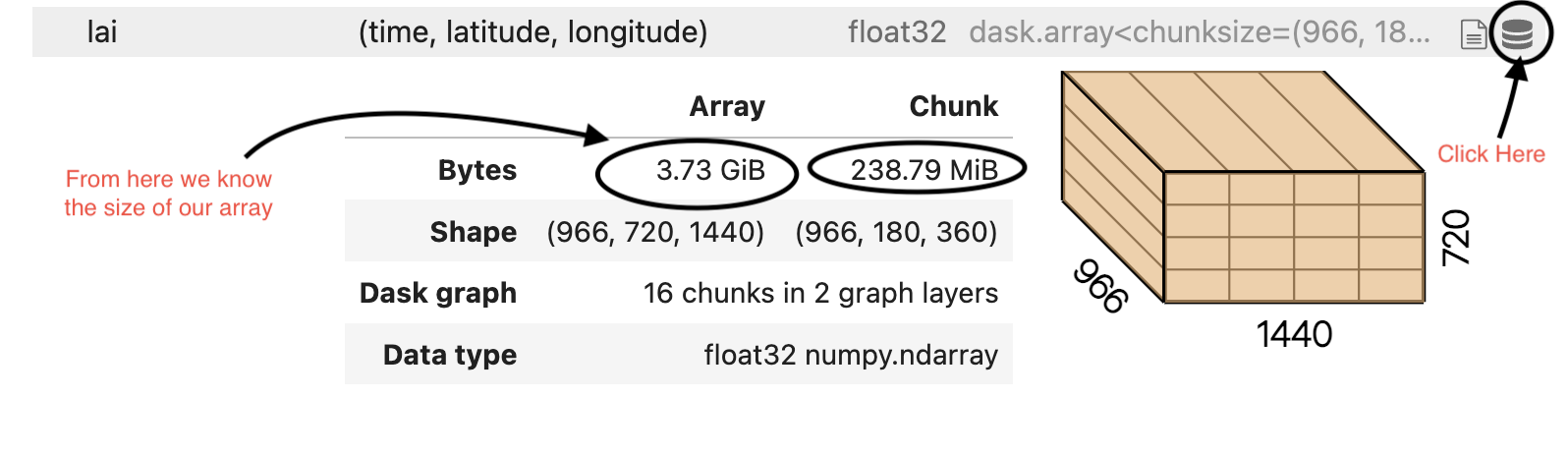
If you look carefully at our dataset, each Data Variable is a ndarray (or dask.array if you have a dask client instantiated) with a chunk size of (966, 180, 360). So basically accessing one data variable would load arrays of dimensions (966, 180, 360) into the computer’s RAM. You can see this information and more details by clicking the icon as indicated in the image below.
When you need to analyze large files, a computer’s memory may not be sufficient anymore.
This is where understanding and using chunking correctly comes into play.
Chunking is splitting a dataset into small pieces.
Original dataset is in one piece,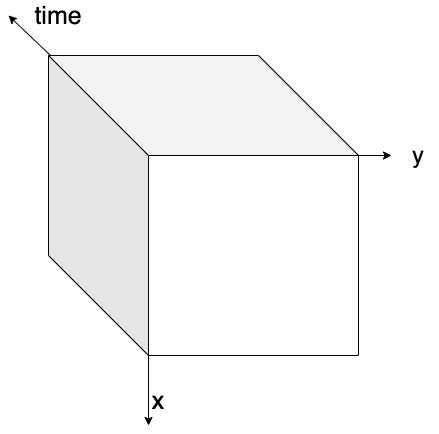
and we split it into several smaller pieces.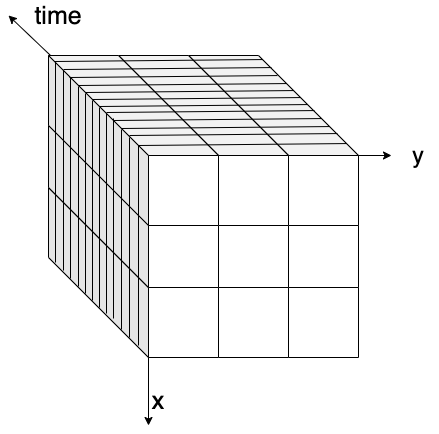
We split it into pieces so that we can process our data block by block or chunk by chunk.
In our case, the data is already chunked, in a cloud-native format ready for analysis and usage - in zarr format
Zarr¶
Zarr’s main characteristics are the following:
- Every chunk of a Zarr dataset is stored as a single file
- Each Data array in a Zarr dataset has a two unique files containing metadata:
- .zattrs for dataset or dataarray general metadatas
- .zarray indicating how the dataarray is chunked, and where to find them on disk or other storage.
Zarr can be considered as an Analysis Ready, cloud optimized data (ARCO) file format!
- Alonso, L., Gans, F., Karasante, I., Ahuja, A., Prapas, I., Kondylatos, S., Papoutsis, I., Panagiotou, E., Mihail, D., Cremer, F., Weber, U., & Carvalhais, N. (2024). SeasFire Cube: A Global Dataset for Seasonal Fire Modeling in the Earth System. Zenodo. 10.5281/ZENODO.13834057