deep-code is a lightweight python tool that comprises a command line interface(CLI)
and Python API providing utilities that aid integration of DeepESDL datasets,
experiments with EarthCODE.
Find out more at: https://
deep_code usage¶
deep_code provides a command-line tool called deep-code, which has several subcommands
providing different utility functions.
Use the --help option with these subcommands to get more details on usage.
The CLI retrieves the Git username and personal access token from a hidden file named .gitaccess. Ensure this file is located in the same directory where you execute the CLI command.
deep-code generate-config¶
Generates starter configuration templates for publishing to EarthCODE openscience catalog.
Usage¶
deep-code generate-config [OPTIONS]Options¶
--output-dir, -o : Output directory (default: current)Examples:¶
deep-code generate-config
deep-code generate-config -o ./configsdeep-code publish¶
Publishes metadata of experiment, workflow and dataset to the EarthCODE open-science catalog
Usage¶
deep-code publish DATASET_CONFIG WORKFLOW_CONFIG [--environment ENVIRONMENT]Arguments¶
DATASET_CONFIG - Path to the dataset configuration YAML file
(e.g., dataset-config.yaml)
WORKFLOW_CONFIG - Path to the workflow configuration YAML file
(e.g., workflow-config.yaml)Options¶
--environment, -e - Target catalog environment:
production (default) | staging | testingFor this tutorial in the EDC environment we’ll directly call the deepcode publish function
Import Packages¶
For this tutorial we will directly use the deep-code package functions, and not the CLI commands. Deep-code is under active development and will soon be available as a downloadable conda package
from deep_code.tools.publish import Publisher
from dotenv import load_dotenv
import os# Get the absolute path of the notebook
# Jupyter notebooks don’t have __file__, so usually you set it manually
notebook_path = os.path.abspath("publish-pangeo.ipynb")
notebook_dir = os.path.dirname(notebook_path)
# Change working directory
os.chdir(notebook_dir)
# Confirm
print("Current Working Directory:", os.getcwd())Current Working Directory: /home/sunnydean/LPS25_Pangeo_x_EarthCODE_Workshop/publishing-to-earthcode/deep-code/deep-code
Required Environment Variables¶
To use deep-code to publish our data we will need to define a couple of environment variables and files.
.gitaccess¶
First we need to give it access to our Github
Creating a .gitaccess File for GitHub Authentication¶
To enable deep-code to publish your work you must create a .gitaccess file with a GitHub personal access token (PAT) that grants repository access.
1. Generate a GitHub Personal Access Token (PAT)¶
- Navigate to GitHub → Settings → Developer settings → Personal access tokens.
- Click “Generate new token”.
- Choose the following scopes to ensure full access:
repo(Full control of repositories — includes fork, pull, push, and read)
- Generate the token and copy it immediately — GitHub won’t show it again.
2. Create the .gitaccess File¶
Create a plain text file named .gitaccess in your project directory or home folder:
github-username: your-git-user
github-token: personal access tokenReplace your-git-user and your-personal-access-token with your actual GitHub username and token.
S3 Configuration for Public Data Access¶
To use deep-code, your data must be publicly accessible. In this example, we use a public S3 bucket hosted at:
https://
If your dataset is hosted in a public cloud location, simply configure the following environment variables to allow deep-code to access your data and automatically generate the appropriate EarthCODE options in a .env file. This will be loaded by load_dotenv() in the cell below
S3_USER_STORAGE_BUCKET=pangeo-test-fires
AWS_DEFAULT_REGION=eu-west-2load_dotenv() # take environment variables
import os
os.environ.get("S3_USER_STORAGE_BUCKET")'pangeo-test-fires'Uploading Data to a Public S3 Bucket with xcube - For Reference Only, We Recommend Uploading your Data to the ESA PRR!¶
The cell bellow provides a quick walkthrough on how to create a publicly accessible S3 bucket and upload data to it using xcube and xarray.
Step 1: Create a Public S3 Bucket¶
- Go to the AWS S3 Console.
- Click Create bucket.
- Enter a unique bucket name, e.g.
pangeo-test-fires. - Choose your AWS Region, e.g.
eu-west-2 (London). - Under Object Ownership, choose Bucket owner enforced (ACLs disabled) — this is the recommended setting for using bucket policies without conflicting with ACLs.
- Scroll down to Block Public Access settings and uncheck all options to allow public access:
- Uncheck:
- Block all public access
- Block public access to buckets and objects granted through new ACLs
- Block public access to buckets and objects granted through any ACLs
- Block public access to buckets and objects granted through new public bucket policies
- Uncheck:
- Acknowledge the warning about making the bucket public.
- Click Create bucket to finish.
Configure Public Read Access¶
To make objects in the bucket publicly accessible, apply the following bucket policy:
Bucket Policy¶
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "PublicReadGetObject",
"Effect": "Allow",
"Principal": "*",
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::pangeo-test-fires/*" <---- replace with your bucket name
}
]
}
Your bucket is now ready for public data access, any data you upload here is publically available.
Step 2: Set Environment Variables¶
To allow xcube to access and write to your S3 bucket in the cell below, define the following environment variables (to be loaded by loadenv()):
S3_USER_STORAGE_BUCKET=pangeo-test-fires
AWS_DEFAULT_REGION=eu-west-2
S3_USER_STORAGE_KEY=<your-aws-access-key-id>
S3_USER_STORAGE_SECRET=<your-aws-secret-access-key>Replace the placeholders with your actual AWS credentials. These are required for programmatic access and uploading data securely.
Step 3: Upload a Zarr Dataset Using xcube¶
xcube is a versatile Python library designed for working with spatiotemporal Earth observation data. It provides a unified interface to access, transform, analyze, and publish multidimensional datasets in cloud-optimized formats like Zarr. One of its key strengths is the ability to interact with a wide variety of storage backends — including local filesystems, object stores like Amazon S3, and remote services — using a consistent data store abstraction.
In this context and the cell below, xcube is used to publish a local Zarr dataset to an S3 bucket, making it publicly accessible for further use in cloud-native geospatial workflows. This is particularly useful for EarthCODE applications or for distributing large EO datasets in an open and scalable manner.
The code example below demonstrates how to:
- Load a local Zarr dataset using
xarray - Configure an authenticated S3 data store through
xcube - Write the dataset into the specified bucket under a desired object key
By using xcube.core.store.new_data_store, the upload process abstracts away the S3 APIs.
# For reference only
# uploaded at: https://pangeo-test-fires.s3.eu-west-2.amazonaws.com/dnbr_dataset.zarr/.zattrs
# import xarray as xr
# from xcube.core.store import new_data_store
# # store data on s3
# root="pangeo-test-fires"
# # Path to the local Zarr dataset
# zarr_path = "../../../wildfires/dnbr_dataset.zarr"
# # Open the Zarr dataset
# ds = xr.open_zarr(zarr_path)
# ds
# store = new_data_store(
# "s3",
# root=root,
# storage_options={
# "anon": False,
# "key": os.environ.get("S3_USER_STORAGE_KEY"),
# "secret": os.environ.get("S3_USER_STORAGE_SECRET"),
# "client_kwargs": {
# "endpoint_url": "https://s3.eu-west-2.amazonaws.com",
# "region_name": os.environ.get("AWS_DEFAULT_REGION")
# }
# },
# )
# store.write_data(ds, "dnbr_dataset.zarr", replace=True)Keeping Your Data Open via ESA Projects Results Repository¶
For the above dataset the storage footprint is small and it will not be operationally used other than for this tutorials - but when hosting bigger datasets one needs to consider that there are costs involved.
The EarthCODE Projects Results Repository offers a powerful, low-friction solution for sharing and preserving the outputs of your ESA-funded Earth observation projects. Instead of worrying about cloud infrastructure, data storage, or long-term access, you can rely on a professionally maintained, FAIR-aligned repository that ensures your results are accessible, reusable, and citable.
Key Benefits¶
- No infrastructure overhead: You don’t need to host or maintain storage — we take care of it.
- Long-term accessibility: Results are stored and served from ESA-managed infrastructure, ensuring persistence and reliability.
- Open science ready: Your datasets are made publicly accessible in cloud-native formats (e.g., Zarr, STAC), supporting downstream use in notebooks, APIs, and platforms like
deep-code. - FAIR-compliant: All submissions are curated to meet Findable, Accessible, Interoperable, and Reusable standards.
- DOI assignment: We help you publish your results with globally recognized identifiers to support citation and traceability.
How to Contribute¶
You can also choose to use the ESA Projects Results Repository — maintained by ESA — to store your project outcomes. The EarthCODE team will fully support you in doing this.
If you would like to store your results and publish them through EarthCODE, simply get in touch with us at:
We’re here to help make your data discoverable, reusable, and impactful.
Looking Ahead¶
In the near future, tools such as deep-code will include built-in support for uploading and registering your results as part of the publishing workflow — making it even easier to share your scientific contributions with the community.
os.chdir(notebook_dir)Using deep-code¶
Great — we’ve uploaded the data and made it publicly accessible. Now, to use deep-code, the final step is to define a few simple metadata entries in a YAML file — one for your dataset (the product) and another for your code (the workflow).
These metadata files allow deep-code to automatically generate STAC Items that follow the EarthCODE Open Science Catalog (OSC) convention, and submit a pull request to register them in the Open Science Catalog.
For Datasets (Products)¶
When defining your dataset metadata, you’ll provide key fields that describe what the dataset contains, where it is stored, and how it aligns with the Open Science Catalog.
Here’s a breakdown of the required fields:
dataset_id: The name of the dataset object within your S3 bucket
collection_id: A unique identifier for the dataset collection
osc_themes: [wildfires] Open Science theme (choose from https://opensciencedata.esa.int/themes/catalog)
documentation_link: Link to relevant documentation, publication, or handbook
access_link: Public S3 URL to the dataset
dataset_status: Status of the dataset: 'ongoing', 'completed', or 'planned'
osc_region: Geographical coverage, e.g. 'global'
cf_parameter: The main geophysical variable, ideally matching a CF standard name or OSC variableNotes¶
osc_themesmust match one of the themes listed at:
https://opensciencedata .esa .int /themes /catalog cf_parametershould reference a well-established variable name, ideally from the Open Science Catalog or CF conventions.
You can explore examples by searching the EarthCODE metadata repository:
Search for “burned-area” in EarthCODE metadata or directly on the osc https://opensciencedata .esa .int /variables /catalog
For Workflows¶
workflow_id: A unique identifier for your workflow
properties:
title: Human-readable title of the workflow
description: A concise summary of what the workflow does
keywords: Relevant scientific or technical keywords
themes: Thematic area(s) of focus (e.g. land, ocean, atmosphere) - see from above example
license: License type (e.g. MIT, Apache-2.0, CC-BY-4.0, proprietary)
jupyter_kernel_info:
name: Name of the execution environment or notebook kernel
python_version: Python version used
env_file: Link to the environment file (YAML) used to create the notebook environment
jupyter_notebook_url: Link to the source notebook (e.g. on GitHub)
contact:
name: Contact person's full name
organization: Affiliated institution or company
links:
rel: "about"
type: "text/html"
href: Link to homepage or personal/institutional profileSee the examples below:
dataset_config="""
dataset_id: dnbr_dataset.zarr
collection_id: pangeo-test
osc_themes:
- 'land'
documentation_link: https://www.sciencedirect.com/science/article/pii/S1470160X22004708#f0035
access_link: s3://pangeo-test-fires
dataset_status: completed
osc_region: global
cf_parameter:
- name: burned-area
"""
with open("dataset_config.yaml", 'w') as f:
f.write(dataset_config)workflow_config="""
workflow_id: "dnbr_workflow_example"
properties:
title: "DNBR Workflow Example"
description: "Demonstrate how to fetch satellite Sentinel-2 data to generate burn severity maps for the assessment of the areas affected by wildfires."
keywords:
- Earth Science
themes:
- land
license: proprietary
jupyter_kernel_info:
name: Pange-Test-Notebook
python_version: 3.11
env_file: "https://github.com/pangeo-data/pangeo-docker-images/blob/master/pangeo-notebook/environment.yml"
jupyter_notebook_url: "https://github.com/pangeo-data/pangeo-openeo-BiDS-2023/blob/main/tutorial/examples/dask/wildfires_daskgateway.ipynb"
contact:
- name: Dean Summers
organization: Lampata
links:
- rel: "about"
type: "text/html"
href: "https://www.lampata.eu/"
"""
with open("workflow_config.yaml", 'w') as f:
f.write(workflow_config)git config --global user.email "your-email@example.com"
git config --global user.name "Your Name"!git config --global user.email "dean@lampata.co.uk"
!git config --global user.name "Dean S"Calling deep-code¶
For this tutorial in the EDC environment we’ll directly call the deepcode publish function via the library code to make sure this code is easily reproducible (as deep-code is currently evolving and changing rapidly with more users publishing to EarthCODE!)
!printenv | grep S3_USER_STORAGE_BUCKETS3_USER_STORAGE_BUCKET=pangeo-test-fires
publisher = Publisher(
dataset_config_path="dataset_config.yaml",
workflow_config_path="workflow_config.yaml",
environment="staging",
)
publisher.publish_all()
# gdm variable:
# https://gcmd.earthdata.nasa.gov/KeywordViewer/scheme/Earth%20Science/436b098d-e4d9-4fbd-9ede-05675e111eee?gtm_keyword=BURNED%20AREA>m_scheme=Earth%20ScienceINFO:root:Forking repository...
INFO:root:Repository forked to sunnydean/open-science-catalog-metadata-staging
INFO:root:Checking local repository...
INFO:root:Cloning forked repository...
Cloning into '/home/sunnydean/temp_repo'...
Updating files: 100% (1776/1776), done.
INFO:root:Repository cloned to /home/sunnydean/temp_repo
INFO:deep_code.tools.publish:Generating STAC collection...
INFO:deep_code.utils.dataset_stac_generator:Attempting to open dataset 'dnbr_dataset.zarr' with configuration: Public store
INFO:httpx:HTTP Request: GET https://raw.githubusercontent.com/IrishMarineInstitute/awesome-erddap/master/erddaps.json "HTTP/1.1 200 OK"
INFO:deep_code.utils.dataset_stac_generator:Successfully opened dataset 'dnbr_dataset.zarr' with configuration: Public store
INFO:deep_code.tools.publish:Variable catalog for burned-ha-mask does not exist. Creating...
Enter GCMD keyword URL or a similar url for burned-ha-mask: https://gcmd.earthdata.nasa.gov/KeywordViewer/scheme/Earth%20Science/436b098d-e4d9-4fbd-9ede-05675e111eee?gtm_keyword=BURNED%20AREA>m_scheme=Earth%20Science
INFO:deep_code.utils.dataset_stac_generator:Added GCMD link for burned-ha-mask catalog https://gcmd.earthdata.nasa.gov/KeywordViewer/scheme/Earth%20Science/436b098d-e4d9-4fbd-9ede-05675e111eee?gtm_keyword=BURNED%20AREA>m_scheme=Earth%20Science.
INFO:deep_code.tools.publish:Variable catalog for delta-nbr does not exist. Creating...
Enter GCMD keyword URL or a similar url for delta-nbr: https://gcmd.earthdata.nasa.gov/KeywordViewer/scheme/Earth%20Science/436b098d-e4d9-4fbd-9ede-05675e111eee?gtm_keyword=BURNED%20AREA>m_scheme=Earth%20Science
INFO:deep_code.utils.dataset_stac_generator:Added GCMD link for delta-nbr catalog https://gcmd.earthdata.nasa.gov/KeywordViewer/scheme/Earth%20Science/436b098d-e4d9-4fbd-9ede-05675e111eee?gtm_keyword=BURNED%20AREA>m_scheme=Earth%20Science.
INFO:deep_code.tools.publish:Generating OGC API Record for the workflow...
INFO:root:Creating new branch: add-new-collection-pangeo-test-20250622220728...
Switched to a new branch 'add-new-collection-pangeo-test-20250622220728'
INFO:deep_code.tools.publish:Adding products/pangeo-test/collection.json to add-new-collection-pangeo-test-20250622220728
INFO:root:Adding new file: products/pangeo-test/collection.json...
INFO:deep_code.tools.publish:Adding variables/burned-ha-mask/catalog.json to add-new-collection-pangeo-test-20250622220728
INFO:root:Adding new file: variables/burned-ha-mask/catalog.json...
INFO:deep_code.tools.publish:Adding variables/delta-nbr/catalog.json to add-new-collection-pangeo-test-20250622220728
INFO:root:Adding new file: variables/delta-nbr/catalog.json...
INFO:deep_code.tools.publish:Adding /home/sunnydean/temp_repo/variables/catalog.json to add-new-collection-pangeo-test-20250622220728
INFO:root:Adding new file: /home/sunnydean/temp_repo/variables/catalog.json...
INFO:deep_code.tools.publish:Adding /home/sunnydean/temp_repo/products/catalog.json to add-new-collection-pangeo-test-20250622220728
INFO:root:Adding new file: /home/sunnydean/temp_repo/products/catalog.json...
INFO:deep_code.tools.publish:Adding /home/sunnydean/temp_repo/projects/deep-earth-system-data-lab/collection.json to add-new-collection-pangeo-test-20250622220728
INFO:root:Adding new file: /home/sunnydean/temp_repo/projects/deep-earth-system-data-lab/collection.json...
INFO:deep_code.tools.publish:Adding workflows/dnbr_workflow_example/record.json to add-new-collection-pangeo-test-20250622220728
INFO:root:Adding new file: workflows/dnbr_workflow_example/record.json...
INFO:deep_code.tools.publish:Adding experiments/dnbr_workflow_example/record.json to add-new-collection-pangeo-test-20250622220728
INFO:root:Adding new file: experiments/dnbr_workflow_example/record.json...
INFO:deep_code.tools.publish:Adding experiments/catalog.json to add-new-collection-pangeo-test-20250622220728
INFO:root:Adding new file: experiments/catalog.json...
INFO:deep_code.tools.publish:Adding workflows/catalog.json to add-new-collection-pangeo-test-20250622220728
INFO:root:Adding new file: workflows/catalog.json...
INFO:root:Committing and pushing changes...
[add-new-collection-pangeo-test-20250622220728 f397b6df] Add new dataset collection: pangeo-test and workflow/experiment: dnbr_workflow_example
10 files changed, 491 insertions(+), 8 deletions(-)
create mode 100644 experiments/dnbr_workflow_example/record.json
create mode 100644 products/pangeo-test/collection.json
create mode 100644 variables/burned-ha-mask/catalog.json
create mode 100644 variables/delta-nbr/catalog.json
create mode 100644 workflows/dnbr_workflow_example/record.json
remote:
remote: Create a pull request for 'add-new-collection-pangeo-test-20250622220728' on GitHub by visiting:
remote: https://github.com/sunnydean/open-science-catalog-metadata-staging/pull/new/add-new-collection-pangeo-test-20250622220728
remote:
To https://github.com/sunnydean/open-science-catalog-metadata-staging.git
* [new branch] add-new-collection-pangeo-test-20250622220728 -> add-new-collection-pangeo-test-20250622220728
INFO:root:Creating a pull request...
branch 'add-new-collection-pangeo-test-20250622220728' set up to track 'origin/add-new-collection-pangeo-test-20250622220728'.
INFO:root:Pull request created: https://github.com/ESA-EarthCODE/open-science-catalog-metadata-staging/pull/129
INFO:deep_code.tools.publish:Pull request created: None
INFO:root:Cleaning up local repository...
INFO:deep_code.tools.publish:Pull request created: None
Reviewing Your Submission¶
Once deep-code completes the submission, it automatically opens a pull request in the EarthCODE Open Science Catalog staging repository. You can:
Check the actual pull request generated by
deep-code:
e.g. ESA-EarthCODE /open -science -catalog -metadata -staging #112
This allows you to inspect exactly what metadata files were created — saving you the time and effort of writing and formatting them manually.Preview and edit your submission in the EarthCODE Staging Dashboard:
https://dashboard .earthcode -staging .earthcode .eox .at/
This UI provides an intuitive way to browse, validate, and refine your submission before it’s merged into the main Open Science Catalog.
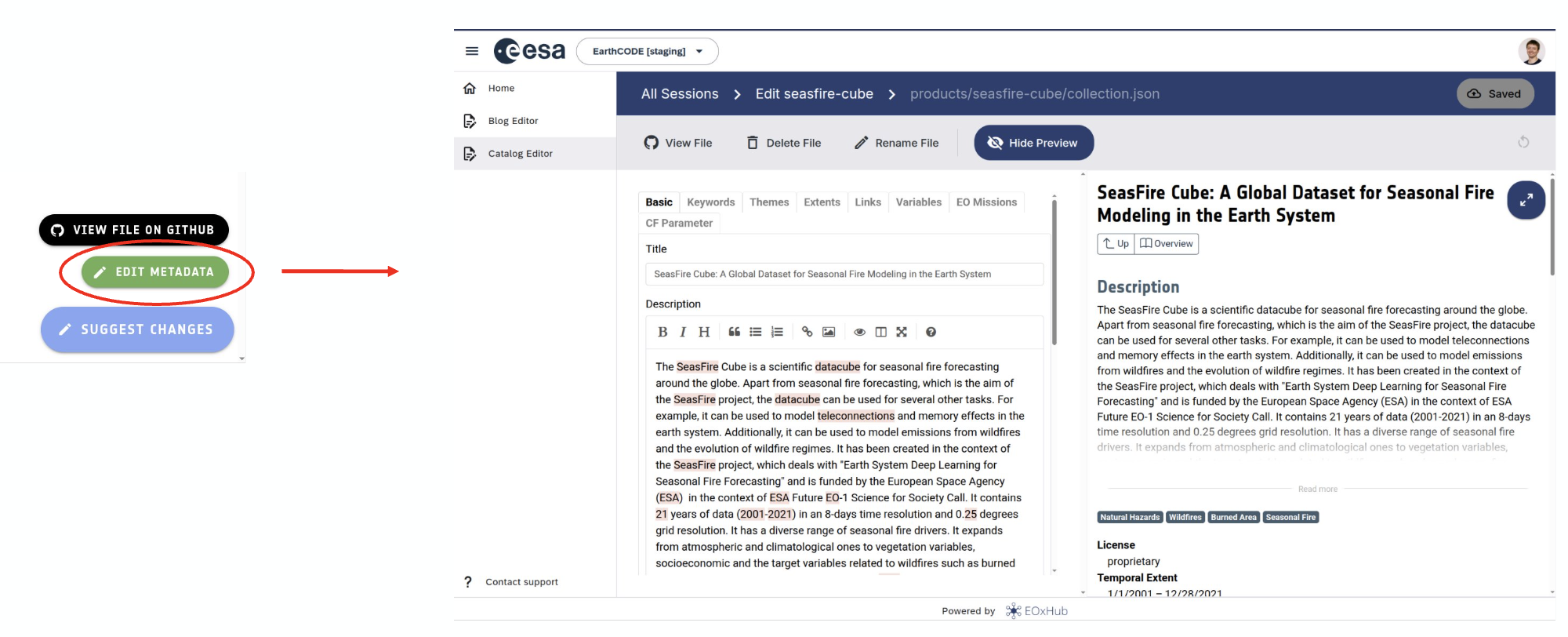
Together, these tools streamline the publishing workflow and help ensure your data and workflows are cleanly documented and catalogued.
# Change back to working directory
os.chdir(notebook_dir)
!pwd
!rm -rf /home/sunnydean/temp_repo//home/sunnydean/LPS25_Pangeo_x_EarthCODE_Workshop/publishing-to-earthcode/deep-code/deep-code